기록, 출석 테이블에 year, month 칼럼을 추가한 이유
기록, 출석에 해당하는 api 를 개발하며, 테이블의 구조가 변경되었다.
아래는 기존 테이블이다. 
그렇다면 변경된 테이블을 살펴보자.

차이점이 보이는가?
각 테이블마다 insert된 날짜의 year, month 를 담을 칼럼이 추가되었다.
사실 insert된 날짜를 아주 상세하게 담고있는 create_at이 있는데 왜 추가를 했는가?
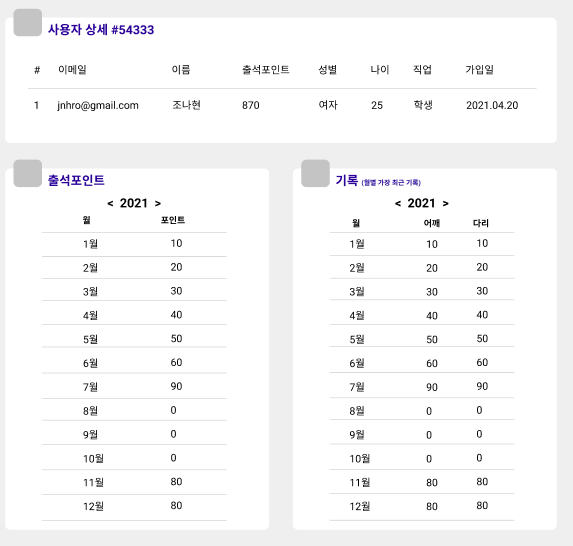
해당 화면에서 필요한 api 사용을 원할하게 하기 위함이었다.
원래라면 설계때부터 이 부분을 염두해두고 신중하게 db를 설계했어야했는데, 쿼리를 짜다보니 이상한 점이 생겼다.
해당 화면은 한 유저의 출석포인트를 해당 연도의 월별로 집계한 결과를 보여준다.
월별로 등록된 출석포인트 row 를 살펴봐야하므로, group by 연도,월 로 사용해야 훨씬 효과적으로 쓸 수 있다.
(기록도 월별 가장 마지막으로 입력된 데이터를 보여준다.)
만약 group by 연도,월 을 사용하기 위해 create_at의 값에서 연도, 월을 분리하여 사용한다면, 데이터의 양이 늘어날수록 테이블 전체의 create_at을 가공해야 하니 효율이 너무 떨어진다.
사실 정답이 명확히 있는 문제인 것은 아닌 것 같다.
단지
movester를 만들 때, 가능한 db의 비지니스 로직처리를 최소화하는 것을 목표로 했기 때문에 미리 데이터를 나눠놓는 것이 좋다고 판단했다.
추후 뭅스터 이벤트 관련 데이터가 대부분 월단위로 산출한 값을 사용할 것이기 때문에, 앞으로 나올 다양한 api들이 year, month를 활용하면 더 적절한 sql 이 나올 수 있을 것이라 예상한다. (리팩터링 책에서는 현재 사용할 기능만 우선 생각하고 짜라고 하는데 이게 참 안된다.😭)
저 화면의 출석포인트를 가져오기 위한 쿼리는 다음과 같다
SELECT attend_month AS month, COUNT(*) * 10 AS attendPoint
FROM attend_point
WHERE user_idx = ${idx}
AND attend_year = ${year}
GROUP BY user_idx, attend_year, attend_month
ORDER BY month ASC
개발하다보니 db 구조가 너무 많이 변경되고 있다.
구조 설계때는 정말 최선을 다해서 많은 고민을 들인 것이었는데, 막상 api를 개발하다보니 부족한게 많이 보인다.
그래도 그때 그때 나은 방향으로 수정하다보면 결국엔 내 최선의 DB 가 되어 있겠지.. 화이팅..!!🏋️♂️
