[JS] 17. 1바이트는 왜 8비트일까?
in JS
컴퓨터의 기본 저장 단위인 1바이트(Byte)는 8비트(bit)로 이루어져 있다.
어째서 8비트일까?
더불어 아스키코드, 안시코드, 유니코드, utf-8에 대해 간략하게 알아보자🤩
1바이트가 8비트인 이유
- 컴퓨터 아키텍쳐가 미국(영문권인 곳)에서 개발, 발전했기 때문.
- 문자를 메모리에 저장하기 위해서는 인코딩을 해야한다. (문자를 전자화, 부호화 하는 것)
- 미국은 아스키코드를 사용했다.
- 아스키코드 : 1바이트 = 8비트로, 7비트(2**7=128)는 데이터 값을, 1비트는 오류검출(패리트비트)을 위해 사용.
- 미국은 아스키코드 내의 문자면 충분했기 때문에, 아스키 문자 인코딩을 기준으로 1바이트가 8비트가 됐다. (한 문자당 하나의 바이트 대응)
ASCII
- American Standard Code for Information Interchange : 미국 정보 교환 표준 부호
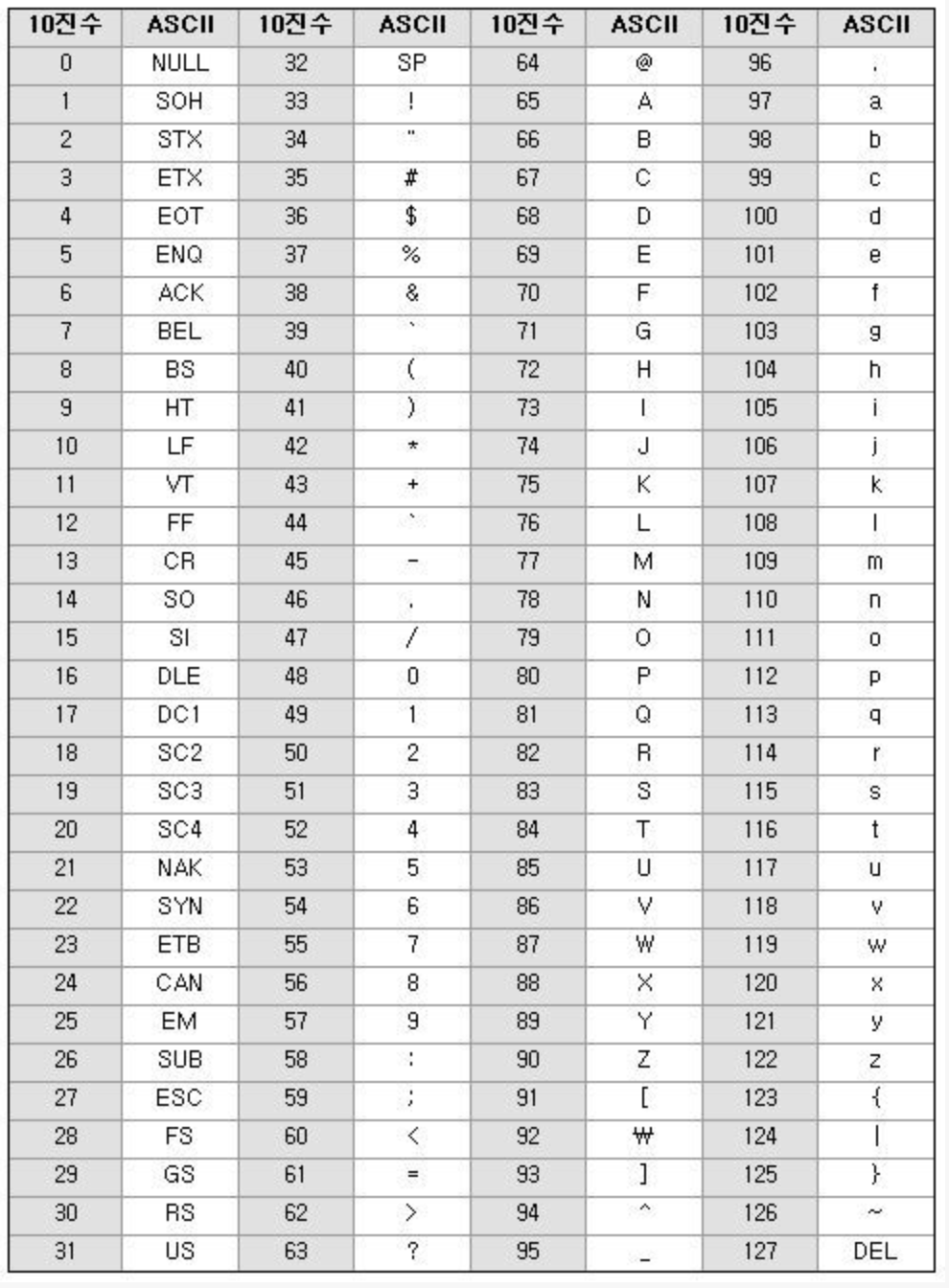
- 1960년대 미국표준협회에서 정의한 표준 코드
- 미국권 문자를 표현하는 문자 인코딩
- 7비트 (2 ** 7 = 128) 만 데이터 값에 사용하고, 1비트는 통신 에러 검출을 위해 사용
- 통신 에러 검출을 위한 비트 = 패리티 비트 (Parity Bit)
- 알파벳, 기호, 숫자 등을 다룰 수 있는 기본적인 문자 코드
- 영문 키보드로 입력할 수 있는 모든 가능성을 담았다.
- 컴퓨터가 글로벌화되면서 > 유럽권을 고려해서 확장해줘…!
- 7비트로는 부족하다.
- 8비트로 확장한 아스키 코드가 등장했다 (ANSI 코드, 확장 아스키 코드)
- 2 ** 8 = 256 개의 값을 담을 수 있게 됐다.
- 이렇게 1바이트만으로 표현되는 방식 : SBCS(Single Byte Character Set)
- 그래도 부족한데…?
- 2개 이상의 바이트 : MBCS(Multi Byte Character Set) (유니코드 제외)
- 한글의 대표적으로, EUC-KR, 한컴 2바이트 코드가 해당한다.
- 확장된 아스키코드 영역의 문자를 2개 합쳐서 표시
- 국가간 다르게 정의하기 때문에 호환성 이슈가 있다.
- 그래도 비유럽 국가 (한국, 일본..) 문자를 담기엔 부족한데?
- 문자 인코딩 방식도 너무 파편화가 됐어..! 통합시키면 안될까?
- 유니코드(Unicode) 등장
- 전 세계 언어의 문자를 정의하기 위한 국제 표준 코드
- 용량이 크게 증가한 2byte (2 ** 16 = 65536)
- 현재는 한 문자를 나타내기 위해 4byte까지 사용한다.
- 파편화된 문자 인코딩 방법도 모두 유니코드로 단일화했다. (기존 아스키코드로 작성된 문서는 utf-8로 완벽 호환)
UTF-8 (가변길이 인코딩)
- 유니코드는 영어는 1바이트, 한글은 2바이트, 다른 특수문자는 3바이트로 언어마다 가변적인 표현의 문제가 있다. > 어떤 글자마다 어떻게 읽어야 하는지 알려줘야한다. (= 유니코드 인코딩 방식)
- 유니코드 인코딩 : 컴퓨터가 어떤 글자를 만났을 때, 얼만큼 읽어야 하는지 미리 말해주는 것.
- 유니코드를 사용하는 인코딩 방식 중 하나
- 영문, 숫자, 기호는 1바이트
- 한글, 한자는 3바이트로 표현
- 아스키 코드와 영문 영역은 100% 호환
- 전세계 모든 언어를 하나의 파일에 쓸 수 있게 됐다.
